Platform
PACTE is a collaborative annotation web platform for text content that integrates an array of practical tools for research groups. It offers three annotation modes: manual, semi-automatic and automatic. Manual annotation is carried out by means of an interface optimized to allow rapid entry of the data enriching a text. The automatic mode is composed of all the specialized and configurable annotation services (named entities, disambiguated terminology, etc.). Semi-automatic annotation, using active learning algorithms, allows training of a prediction model with minimal annotation, requiring less effort to annotate large text corpora. See below for more information on these tools.
The collaborative nature of the PACTE web platform allows sharing of analyses and annotations with other researchers, thereby facilitating cooperation and opening the door to large-scale multi-partner studies. PACTE generates important gains in productivity by significantly reducing the time spent on analysis, while improving consistency.
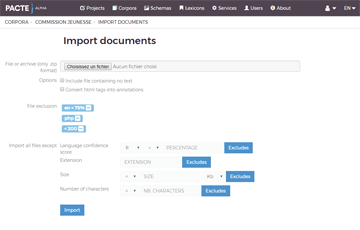
Manage large text corpora
Create, import and access your corpora.
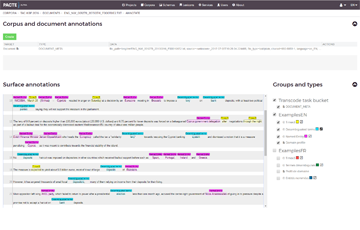
Manual annotation
Create and modify your annotations.
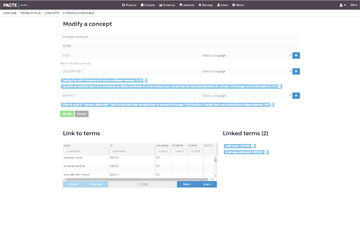
Define your terminology
Consult an existing lexicon or build your own!
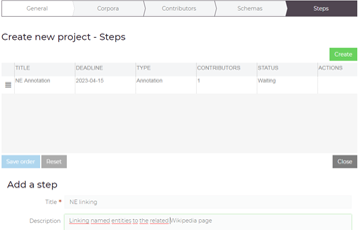
Create whole annotation projects
Assign annotation tasks to team members.
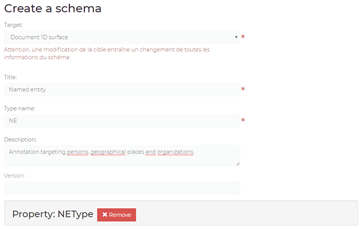
Define custom annotation schemas
Structure the information you need to enrich your documents.

Start annotation services
Launch one of our linguistic, lexical or semantic annotation tools.
Semi-automatic annotation
No service does what you need it to do? Train your own, customized annotator!
Bilingual platform
Work in English or in French, depending on team members’ preferences.
Search by annotation
Find the relevant documents according to annotation type.












